日拱一卒,功不唐捐——程序设计练习笔记
PAT (Basic Level) Practice
1007 素数对猜想
“素数对猜想”认为“存在无穷多对相邻且差为 2 的素数”。
现给定任意正整数 N (<105),请计算不超过 N 的满足猜想的素数对的个数。
输入格式:
输入在一行给出正整数 N 。
输出格式:
在一行中输出不超过 N 的满足猜想的素数对的个数。
输入样例:
20
输出样例:
4
代码:
积累点: 更高效地判断素数,无需循环至n-1,而是利用sqrt()函数。
#include <iostream>
#include <math.h>
using namespace std;
bool panduan(int n) {
for (int i = 2; i <= sqrt(n); i++) {
if (n % i == 0)
return false;
}
return true;
}
int main() {
int n, cnt = 0;
cin >> n;
for (int i = 3; i <= n - 2; i++) {
if (panduan(i) && panduan(i + 2))
cnt++;
}
cout << cnt;
return 0;
}
1008 数组元素循环右移问题
一个数组 A 中存有 N(>0)个整数,在不允许使用另外数组的前提下,将每个整数循环向右移 M(≥0)个位置(最后M个数循环移至最前面的 M 个位置)。如果需要考虑程序移动数据的次数尽量少,要如何设计移动的方法?
输入格式:
每个输入包含一个测试用例,第 1 行输入 N(1≤ N ≤100)和 M(≥0);第 2 行输入 N 个整数,之间用空格分隔。
输出格式:
在一行中输出循环右移 M 位以后的整数序列,之间用空格分隔,序列结尾不能有多余空格。
输入样例:
6 2
1 2 3 4 5 6
输出样例:
5 6 1 2 3 4
代码:
积累点: 循环移动的算法。但是如何提高效率仍待学习!
#include <iostream>
using namespace std;
void rightmove(int* p, int N, int M) {
for (int i = N - 1; i > N - 1 - M; i--) {
int temp = p[N - 1];
for (int i = N - 1; i > 0; i--) {
p[i] = p[i - 1];
}
p[0] = temp;
}
}
int main() {
int N, M;
cin >> N >> M;
int* p = new int[N];
for (int i = 0; i < N; i++)
cin >> p[i];
rightmove(p, N, M);
for (int i = 0; i < N; i++) {
cout << p[i];
if (i != N - 1)
cout << " ";
}
}
1009 说反话
给定一句英语,要求你编写程序,将句中所有单词的顺序颠倒输出。
输入格式:
测试输入包含一个测试用例,在一行内给出总长度不超过 80 的字符串。字符串由若干单词和若干空格组成,其中单词是由英文字母(大小写有区分)组成的字符串,单词之间用 1 个空格分开,输入保证句子末尾没有多余的空格。
输出格式:
每个测试用例的输出占一行,输出倒序后的句子。
输入样例:
Hello World Here I Come
输出样例:
Come I Here World Hello
代码:
积累点: 统计字符串中的空格个数(获取单词数)
一些感慨:
- 这题花了很多时间在想如何设计一个reverse函数逆序输出单词,其实只要使用string数组的倒序输出即可。问题可能是出在对于存储字符串的变量类型的选取上。
- 划分单词的简便做法是寻找空格作为间隔,因为单词的长度是无法预知的。
- 对字符串的处理始终是一大难点。char类型指针太复杂,string类型不会用···
#include <iostream>
#include <string>
using namespace std;
int main() {
int num = 0;
char ch; //接收单词后的空格或回车
string str[80];
for (int i = 0; i < 80; i++) {
cin >> str[i];
ch = getchar();
if (ch == '\n')
break;
num++;
}
for (int i = num; i >= 0; i--) {
cout << str[i];
if (i != 0)
cout << " ";
}
return 0;
}
附:尚未解决的错误代码
#include <iostream>
#include <string>
using namespace std;
void reverse(char word[][80], int num) {
string temp;
for (int i = 0; i < num / 2; i++) {
temp = word[i];
*word[i] = *word[num - i];
strcpy_s(word[num - i],temp.c_str());
}
}
int main() {
int len = 0,num = 0;
string str;
char word[80][80];
getline(cin,str);
len = str.length();
for (int i = 0; i < len; i++) {
if (str[i] == ' ' ) {
num++;
}
else {
strcpy_s(word[num],str.c_str());
}
}
cout << *word;
cout << endl;
reverse(word, num);
for (int j = num; j >= 0; j++) {
cout << word[j];
}
}
1010 一元多项式求导
设计函数求一元多项式的导数。
输入格式:
以指数递降方式输入多项式非零项系数和指数(绝对值均为不超过 1000 的整数)。数字间以空格分隔。
输出格式:
以与输入相同的格式输出导数多项式非零项的系数和指数。数字间以空格分隔,但结尾不能有多余空格。注意“零多项式”的指数和系数都是 0,但是表示为 0 0。
输入样例:
3 4 -5 2 6 1 -2 0
输出样例:
12 3 -10 1 6 0
代码:
一些感慨:
- 思考不够全面,只考虑了输入本身是“零多项式”的情况,未考虑求导后是“零多项式”,花了好久在调试上···
- 关于个数的计算始终容易出错,常常顾此失彼
#include <iostream>
using namespace std;
struct polynomial {
int co;
int idx;
};
int main() {
polynomial pl[100] = { 0,0 };
char ch;
int i;
int num = 0;
for (i = 0; i < 100; i++) {
cin >> pl[i].co;
cin >> pl[i].idx;
ch = getchar();
if (ch == '\n')
break;
}
i++; //用i表示项数,但是当ch接收到回车时会直接跳出for循环,导致i漏加一次,故在此补上
if (i == 1 && pl[0].co == 0 && pl[0].idx == 0) {
cout << 0 << " " << 0;
return 0;
}
for (int j = 0; j < i; j++) {
pl[j].co *= pl[j].idx;
if (pl[j].idx != 0)
pl[j].idx--;
if (pl[j].co == 0)
pl[j].idx = 0;
else
num++;
}
for (int j = 0; j < i; j++) {
if (pl[j].co && j)
cout << " ";
if (pl[j].co != 0) {
cout << pl[j].co << " " << pl[j].idx;
}
}
if (num == 0)
cout << 0 << " " << 0;
return 0;
}
1011 A+B 和 C
给定区间 [−2^31^,2^31^] 内的 3 个整数 A、B 和 C,请判断 A+B 是否大于 C。
输入格式:
输入第 1 行给出正整数 T (≤10),是测试用例的个数。随后给出 T 组测试用例,每组占一行,顺序给出 A、B 和 C。整数间以空格分隔。
输出格式:
对每组测试用例,在一行中输出 Case #X: true 如果 A+B>C,否则输出 Case #X: false,其中 X 是测试用例的编号(从 1 开始)。
输入样例:
4
1 2 3
2 3 4
2147483647 0 2147483646
0 -2147483648 -2147483647
输出样例:
Case #1: false
Case #2: true
Case #3: true
Case #4: false
代码:
积累点: int型: [−2^31^,2^31^-1] , 即 -2147483648 ~ 2147483647,故此题使用int类型在两数相加时可能超出范围
#include <iostream>
using namespace std;
struct number {
long long int a;
long long int b;
long long int c;
};
void judge(number num, long long int i) {
if (num.a + num.b > num.c)
cout << "Case #" << i + 1 << ": true";
else
cout << "Case #" << i + 1 << ": false";
}
int main() {
number num[10];
int t, i;
cin >> t;
for (i = 0; i < t; i++) {
cin >> num[i].a >> num[i].b >> num[i].c;
}
for (i = 0; i < t; i++) {
judge(num[i], i);
cout << endl;
}
return 0;
}
1012 数字分类
给定一系列正整数,请按要求对数字进行分类,并输出以下 5 个数字:
- A1 = 能被 5 整除的数字中所有偶数的和;
- A2 = 将被 5 除后余 1 的数字按给出顺序进行交错求和,即计算 n1−n2+n3−n4⋯;
- A3 = 被 5 除后余 2 的数字的个数;
- A4 = 被 5 除后余 3 的数字的平均数,精确到小数点后 1 位;
- A5 = 被 5 除后余 4 的数字中最大数字。
输入格式:
每个输入包含 1 个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N,随后给出 N 个不超过 1000 的待分类的正整数。数字间以空格分隔。
输出格式:
对给定的 N 个正整数,按题目要求计算 A1~A5 并在一行中顺序输出。数字间以空格分隔,但行末不得有多余空格。
若分类之后某一类不存在数字,则在相应位置输出 N。
输入样例 1:
13 1 2 3 4 5 6 7 8 9 10 20 16 18
输出样例 1:
30 11 2 9.7 9
输入样例 2:
8 1 2 4 5 6 7 9 16
输出样例 2:
N 11 2 N 9
代码:
积累点:
如何设置精度(C++比C语言更繁琐一些,故选择了用C的printf)
- cout是C++的标准输出流,在iomanip头文件中有对其进行格式操作的函数
由于浮点数的不精确性,不可以直接使用==进行判断(和 0 比较),而应设置一个较小的常量进行比较判断
- 两个浮点数相比较同理,应使用fabs()函数对浮点数之差取绝对值,再与较小常量比较(记得加头文件)
尽可能少用for循环,合并简化代码(比如判断模 5 的余数不需要每次遍历一遍,在一个for循环内用 if-else 语句或是 switch-case 语句即可)
#include <iostream>
using namespace std;
float TOLERANCE = 0.0001;
int main() {
int n, i;
cin >> n;
int num[1000];
int a1 = 0, a2 = 0, a3 = 0, a5 = 0;
float a4 = 0;
int numa2 = 0, numa4 = 0;
for (i = 0; i < n; i++) {
cin >> num[i];
if (num[i] % 5 == 0 && num[i] % 2 == 0)
a1 += num[i];
else if (num[i] % 5 == 1) {
numa2++;
if (numa2 % 2 == 0)
a2 -= num[i];
else
a2 += num[i];
}
else if (num[i] % 5 == 2)
a3++;
else if (num[i] % 5 == 3) {
numa4++;
a4 += num[i];
}
else if (num[i] % 5 == 4) {
if (num[i] > a5)
a5 = num[i];
}
}
if (a1 != 0)
cout << a1 << " ";
else
cout << "N" << " ";
if (numa2 != 0)
cout << a2 << " ";
else
cout << "N" << " ";
if (a3 != 0)
cout << a3 << " ";
else
cout << "N" << " ";
a4 /= numa4;
if (a4 > TOLERANCE) {
printf("%.1f", a4);
cout << " ";
}
else
cout << "N" << " ";
if (a5 != 0)
cout << a5;
else
cout << "N";
}
1013 数素数
令 P_i 表示第 i 个素数。现任给两个正整数 M ≤ N ≤ 104,请输出 P_M 到 P_N 的所有素数。
输入格式:
输入在一行中给出 M 和 N,其间以空格分隔。
输出格式:
输出从 P_M 到 P_N 的所有素数,每 10 个数字占 1 行,其间以空格分隔,但行末不得有多余空格。
输入样例:
5 27
输出样例:
11 13 17 19 23 29 31 37 41 43
47 53 59 61 67 71 73 79 83 89
97 101 103
代码:
易错点:
判断素数时应以 2 为起始点而不是 0 或 1,否则会出错
21~24行的部分需要写在大的if语句内,否则下次进入for循环时pm的值会更新(idx仍然等于m)
#include <iostream>
#include <math.h>
using namespace std;
bool prime(int num) {
for (int i = 2; i <= sqrt(num); i++) {
if (num % i == 0)
return false;
}
return true;
}
int main() {
int m, n, pm = 0, pn = 0;
cin >> m >> n;
int idx = 0;
int i;
for (i = 2; idx != n; i++) {
if (prime(i) == true) {
idx++;
if (idx == m)
pm = i;
if (idx == n)
pn = i;
}
}
int ten = 0;
for (i = pm; i <= pn; i++) {
if (prime(i) == true) {
cout << i;
ten++;
if (ten % 10 == 0)
cout << endl;
else if (i != pn)
cout << " ";
}
}
return 0;
}
另解:
- 数组长度要尽可能大,否则会出现越界(段错误)
- 注意区分下标:数组下标从 0 开始,而素数元素对应的下标是从 1 开始
#include <iostream>
#include <math.h>
using namespace std;
bool prime(int num) {
for (int i = 2; i <= sqrt(num); i++) {
if (num % i == 0)
return false;
}
return true;
}
int main() {
int m, n;
cin >> m >> n;
int idx = 0;
int i;
int pr[10000] = { 0 };
for (i = 2; idx != n; i++) {
if (prime(i) == true) {
idx++;
pr[idx] = i;
if (idx == m)
m = idx;
if (idx == n)
n = idx;
}
}
int ten = 0;
for (i = m; i <= n; i++) {
cout << pr[i];
ten++;
if (ten % 10 == 0)
cout << endl;
else if (i != n)
cout << " ";
}
return 0;
}
1014 福尔摩斯的约会
大侦探福尔摩斯接到一张奇怪的字条:
我们约会吧!
3485djDkxh4hhGE
2984akDfkkkkggEdsb
s&hgsfdk
d&Hyscvnm
大侦探很快就明白了,字条上奇怪的乱码实际上就是约会的时间星期四 14:04,因为前面两字符串中第 1 对相同的大写英文字母(大小写有区分)是第 4 个字母 D,代表星期四;第 2 对相同的字符是 E ,那是第 5 个英文字母,代表一天里的第 14 个钟头(于是一天的 0 点到 23 点由数字 0 到 9、以及大写字母 A 到 N 表示);后面两字符串第 1 对相同的英文字母 s 出现在第 4 个位置(从 0 开始计数)上,代表第 4 分钟。现给定两对字符串,请帮助福尔摩斯解码得到约会的时间。
输入格式:
输入在 4 行中分别给出 4 个非空、不包含空格、且长度不超过 60 的字符串。
输出格式:
在一行中输出约会的时间,格式为 DAY HH:MM,其中 DAY 是某星期的 3 字符缩写,即 MON 表示星期一,TUE 表示星期二,WED 表示星期三,THU 表示星期四,FRI 表示星期五,SAT 表示星期六,SUN 表示星期日。题目输入保证每个测试存在唯一解。
输入样例:
3485djDkxh4hhGE
2984akDfkkkkggEdsb
s&hgsfdk
d&Hyscvnm
输出样例:
THU 14:04
代码:
易错点:
- 本题细节较多,尤其是对输入字符范围的判断,DAY需要是A~G,由于没有说明,比起HOUR容易漏掉
- 完成寻找之后要立即跳出循环,以防后面还有相同的字符输出
积累点:
- 如何设置输出固定位数的整数
- 字符串相关操作,对指针的运用
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
char ch1[60], ch2[60], ch3[60], ch4[60];
cin >> ch1 >> ch2 >> ch3 >> ch4;
char* a = ch1, * b = ch2, * c = ch3, * d = ch4;
char date = ' '; int hour = -1;
int n2 = -1;
bool flag = false;
while (*a != ' ' && *b != ' ') {
if (*a == *b && flag == true && ((*a >= 'A' && *a <= 'N') || (*a <= '9' && *a >= '0'))) {
if (*a <= 'N' && *a >= 'A')
hour = (*a - 'A' + 1) + 9;
else
hour = (*a - '0');
break;
}
if (*a == *b && flag == false && *a >= 'A' && *a <= 'G') {
flag = true;
date = *a;
}
a++; b++;
}
while (*c != ' ' && *d != ' ') {
if (*c == *d && ((*c >= 'a' && *c <= 'z') || (*c >= 'A' && *c <= 'Z'))) {
n2 = c - ch3;
break;
}
c++, d++;
}
switch (date) {
case 'A':
cout << "MON" << " ";
break;
case 'B':
cout << "TUE" << " ";
break;
case 'C':
cout << "WED" << " ";
break;
case 'D':
cout << "THU" << " ";
break;
case 'E':
cout << "FRI" << " ";
break;
case 'F':
cout << "SAT" << " ";
break;
case 'G':
cout << "SUN" << " ";
break;
}
cout << setfill('0') << setw(2) << hour << ":" << setfill('0') << setw(2) << n2;
return 0;
}
1015 德才论
宋代史学家司马光在《资治通鉴》中有一段著名的“德才论”:“是故才德全尽谓之圣人,才德兼亡谓之愚人,德胜才谓之君子,才胜德谓之小人。凡取人之术,苟不得圣人,君子而与之,与其得小人,不若得愚人。”
现给出一批考生的德才分数,请根据司马光的理论给出录取排名。
输入格式:
输入第一行给出 3 个正整数,分别为:N(≤105),即考生总数;L(≥60),为录取最低分数线,即德分和才分均不低于 L 的考生才有资格被考虑录取;H(<100),为优先录取线——德分和才分均不低于此线的被定义为“才德全尽”,此类考生按德才总分从高到低排序;才分不到但德分到优先录取线的一类考生属于“德胜才”,也按总分排序,但排在第一类考生之后;德才分均低于 H,但是德分不低于才分的考生属于“才德兼亡”但尚有“德胜才”者,按总分排序,但排在第二类考生之后;其他达到最低线 L 的考生也按总分排序,但排在第三类考生之后。
随后 N 行,每行给出一位考生的信息,包括:准考证号 德分 才分,其中准考证号为 8 位整数,德才分为区间 [0, 100] 内的整数。数字间以空格分隔。
输出格式:
输出第一行首先给出达到最低分数线的考生人数 M,随后 M 行,每行按照输入格式输出一位考生的信息,考生按输入中说明的规则从高到低排序。当某类考生中有多人总分相同时,按其德分降序排列;若德分也并列,则按准考证号的升序输出。
输入样例:
14 60 80
10000001 64 90
10000002 90 60
10000011 85 80
10000003 85 80
10000004 80 85
10000005 82 77
10000006 83 76
10000007 90 78
10000008 75 79
10000009 59 90
10000010 88 45
10000012 80 100
10000013 90 99
10000014 66 60
输出样例:
12
10000013 90 99
10000012 80 100
10000003 85 80
10000011 85 80
10000004 80 85
10000007 90 78
10000006 83 76
10000005 82 77
10000002 90 60
10000014 66 60
10000008 75 79
10000001 64 90
代码:
易错点:
- 数组大小越界,有几个测试点答案错误是因为stu1~stu4的数组给的不够大
- 运行超时,原先采用选择排序,使用库函数sort(自定义)后解决
#include <iostream>
#include <algorithm>
using namespace std;
struct Student {
int num;
int dgrade;
int cgrade;
int total;
};
bool cmp(const Student& stu1, const Student& stu2) {
if (stu1.total != stu2.total)
return stu1.total > stu2.total;
else if (stu1.dgrade != stu2.dgrade)
return stu1.dgrade > stu2.dgrade;
else
return stu1.num < stu2.num;
}
int main() {
int N, L, H;
cin >> N >> L >> H;
int n = 0, n1 = 0, n2 = 0, n3 = 0, n4 = 0;
Student stu[100000] = {}, stu1[100000], stu2[100000], stu3[100000], stu4[100000];
for (int i = 0; i < N; i++) {
cin >> stu[i].num >> stu[i].dgrade >> stu[i].cgrade;
stu[i].total = stu[i].dgrade + stu[i].cgrade;
if (stu[i].dgrade >= H && stu[i].cgrade >= H) {
stu1[n1] = stu[i];
n1++;
n++;
}
else if (stu[i].dgrade >= H && stu[i].cgrade < H && stu[i].cgrade >= L) {
stu2[n2] = stu[i];
n2++;
n++;
}
else if (stu[i].dgrade < H && stu[i].cgrade < H && stu[i].dgrade >= L && stu[i].cgrade >= L && stu[i].dgrade >= stu[i].cgrade) {
stu3[n3] = stu[i];
n3++;
n++;
}
else if (stu[i].dgrade >= L && stu[i].cgrade >= L) {
stu4[n4] = stu[i];
n4++;
n++;
}
}
sort(stu1, stu1 + n1, cmp);
sort(stu2, stu2 + n2, cmp);
sort(stu3, stu3 + n3, cmp);
sort(stu4, stu4 + n4, cmp);
cout << n << endl;
for (int i = 0; i < n1; i++) {
cout << stu1[i].num << " " << stu1[i].dgrade << " " << stu1[i].cgrade << endl;
}
for (int i = 0; i < n2; i++) {
cout << stu2[i].num << " " << stu2[i].dgrade << " " << stu2[i].cgrade << endl;
}
for (int i = 0; i < n3; i++) {
cout << stu3[i].num << " " << stu3[i].dgrade << " " << stu3[i].cgrade << endl;
}
for (int i = 0; i < n4; i++) {
cout << stu4[i].num << " " << stu4[i].dgrade << " " << stu4[i].cgrade;
if (i != n4 - 1)
cout << endl;
}
return 0;
}
1016 部分A+B
正整数 A 的“DA(为 1 位整数)部分”定义为由 A 中所有 DA 组成的新整数 PA。例如:给定 A=3862767,DA=6,则 A 的“6 部分”PA 是 66,因为 A 中有 2 个 6。
现给定 A、DA、B、DB,请编写程序计算 PA+PB。
输入格式:
输入在一行中依次给出 A、DA、B、DB,中间以空格分隔,其中 0<A,B<109。
输出格式:
在一行中输出 PA+PB 的值。
输入样例 1:
3862767 6 13530293 3
输出样例 1:
399
输入样例 2:
3862767 1 13530293 8
输出样例 2:
0
代码:
易错点: for循环判断a[i]、b[i]是否结尾的时候如果使用 ’ ’ 而非 ‘\0’ 会导致结果出错,原因未知
(后来思考是因为我的char数组没有初始化,直接用是否为 ’ ’ 来判断是不恰当的,但是即使改为a[15]={ },还是会出现段错误)
#include <iostream>
#include <math.h> //本来算pa是通过循环pa += pow(10, i) * da;的,因此加了该头文件
using namespace std;
int main() {
char a[15], b[15], ca, cb;
cin >> a >> ca >> b >> cb;
int da = ca - '0', db = cb - '0';
int i, na = 0, nb = 0;
for (i = 0; a[i] != '\0'; i++) {
if (a[i] == ca)
na++;
}
for (i = 0; b[i] != '\0'; i++) {
if (b[i] == cb)
nb++;
}
int pa = 0, pb = 0;
if (na != 0) {
for (i = 0; i < na; i++)
pa = pa * 10 + da;
}
if (nb != 0) {
for (i = 0; i < nb; i++)
pb = pb * 10 + db;
}
cout << pa + pb;
return 0;
}
1017 A除以B
本题要求计算 A/B,其中 A 是不超过 1000 位的正整数,B 是 1 位正整数。你需要输出商数 Q 和余数 R,使得 A=B×Q+R 成立。
输入格式:
输入在一行中依次给出 A 和 B,中间以 1 空格分隔。
输出格式:
在一行中依次输出 Q 和 R,中间以 1 空格分隔。
输入样例:
123456789050987654321 7
输出样例:
17636684150141093474 3
代码:
易错点:
- 商的输出:在出现非0数之前,0不能输出;若商为0,需要额外讨论
- 数组容量需要多提供,只给1000会出错(猜测可能是因为测试点输入的开头有部分0)
#include <iostream>
using namespace std;
int main() {
char a[1001] = {}, q[1001] = {};
int n[1001] = { 0 };
int b, r, i;
bool flag = false; //用于标记先前是否有非0数输出,若均无,则当前为0的数不能输出
cin >> a >> b;
for (i = 0; a[i] != '\0'; i++) {
n[i] += a[i] - '0';
q[i] = (n[i] / b) + '0';
r = n[i] % b;
n[i + 1] += (n[i] % b) * 10;
}
for (int j = 0; q[j] != '\0'; j++) {
if (flag == true || q[j] != '0') {
cout << q[j];
flag = true;
}
}
if (flag == false)
cout << 0; //如果商为0,那么先前的for循环始终没有输出,故此处补充输出0
cout << " " << r;
return 0;
}
1018 锤子剪刀布
大家应该都会玩“锤子剪刀布”的游戏:两人同时给出手势,胜负规则如图所示:
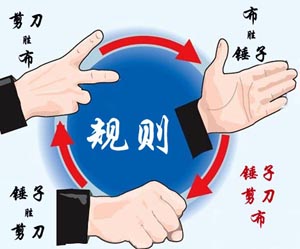
现给出两人的交锋记录,请统计双方的胜、平、负次数,并且给出双方分别出什么手势的胜算最大。
输入格式:
输入第 1 行给出正整数 N(≤105),即双方交锋的次数。随后 N 行,每行给出一次交锋的信息,即甲、乙双方同时给出的的手势。C 代表“锤子”、J 代表“剪刀”、B 代表“布”,第 1 个字母代表甲方,第 2 个代表乙方,中间有 1 个空格。
输出格式:
输出第 1、2 行分别给出甲、乙的胜、平、负次数,数字间以 1 个空格分隔。第 3 行给出两个字母,分别代表甲、乙获胜次数最多的手势,中间有 1 个空格。如果解不唯一,则输出按字母序最小的解。
输入样例:
10
C J
J B
C B
B B
B C
C C
C B
J B
B C
J J
输出样例:
5 3 2
2 3 5
B B
代码:
#include <iostream>
#include <algorithm>
using namespace std;
char find_max_ch(char ch[], int n) {
int i = 0, j = 0, k = 0;
for (int a = 0; a < n; a++) {
if (ch[a] == 'C')
i++;
else if (ch[a] == 'J')
j++;
else
k++;
}
if (i > j && i > k)
return 'C';
else if (j > i && j > k)
return 'J';
else if (k > i && k > j)
return 'B';
else if (i == j && i > k)
return 'C';
else
return 'B';
}
int main() {
int N;
cin >> N;
char ch1[100000], ch2[100000];
char win1[100000], win2[100000];
int n1 = 0, n2 = 0, n3 = 0;
for (int i = 0; i < N; i++) {
cin >> ch1[i] >> ch2[i];
if (ch1[i] == 'C' && ch2[i] == 'J' || ch1[i] == 'J' && ch2[i] == 'B' || ch1[i] == 'B' && ch2[i] == 'C') {
win1[n1] = ch1[i];
n1++;
}
else if (ch1[i] == 'C' && ch2[i] == 'C' || ch1[i] == 'J' && ch2[i] == 'J' || ch1[i] == 'B' && ch2[i] == 'B') {
n3++;
}
else {
win2[n2] = ch2[i];
n2++;
}
}
cout << n1 << " " << n3 << " " << n2 << endl;
cout << n2 << " " << n3 << " " << n1 << endl;
cout << find_max_ch(win1, n1) << " " << find_max_ch(win2, n2);
return 0;
}
1019 数字黑洞
给定任一个各位数字不完全相同的 4 位正整数,如果我们先把 4 个数字按非递增排序,再按非递减排序,然后用第 1 个数字减第 2 个数字,将得到一个新的数字。一直重复这样做,我们很快会停在有“数字黑洞”之称的 6174,这个神奇的数字也叫 Kaprekar 常数。
例如,我们从6767开始,将得到
7766 - 6677 = 1089
9810 - 0189 = 9621
9621 - 1269 = 8352
8532 - 2358 = 6174
7641 - 1467 = 6174
... ...
现给定任意 4 位正整数,请编写程序演示到达黑洞的过程。
输入格式:
输入给出一个 (0,104) 区间内的正整数 N。
输出格式:
如果 N 的 4 位数字全相等,则在一行内输出 N - N = 0000;否则将计算的每一步在一行内输出,直到 6174 作为差出现,输出格式见样例。注意每个数字按 4 位数格式输出。
输入样例 1:
6767
输出样例 1:
7766 - 6677 = 1089
9810 - 0189 = 9621
9621 - 1269 = 8352
8532 - 2358 = 6174
输入样例 2:
2222
输出样例 2:
2222 - 2222 = 0000
代码:
易错点:
- 需要为输入、输出不满4位的情况进行补0
- 数组大小的设置,需要多提供
#include <iostream>
#include <algorithm>
#include <cstring>
#include <math.h>
#include <iomanip>
using namespace std;
bool cmp1(char a1, char a2) {
return a1 < a2;
}
bool cmp2(char a1, char a2) {
return a1 > a2;
}
int main() {
char ori[10], a[10], b[10];
int dif = 0, flag = 0;
cin >> ori;
while (strlen(ori) < 4) {
ori[strlen(ori)] = '0';
}
int up = -1, down = -2;
while (flag != 6174 && up - down != 0) {
up = 0, down = 0;
sort(ori, ori + 4, cmp1);
strcpy(a, ori);
sort(ori, ori + 4, cmp2);
strcpy(b, ori);
for (int i = 3; i >= 0; i--) {
up += (a[i] - '0') * pow(10, i);
down += (b[i] - '0') * pow(10, i);
}
dif = up - down;
flag = dif;
cout << setfill('0') << setw(4) << up << " - ";
cout << setfill('0') << setw(4) << down << " = ";
cout << setfill('0') << setw(4) << up - down << endl;
for (int i = 3; i >= 0; i--) {
ori[i] = (dif % 10) + '0';
dif /= 10;
}
}
return 0;
}
1020 月饼
月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼。现给定所有种类月饼的库存量、总售价、以及市场的最大需求量,请你计算可以获得的最大收益是多少。
注意:销售时允许取出一部分库存。样例给出的情形是这样的:假如我们有 3 种月饼,其库存量分别为 18、15、10 万吨,总售价分别为 75、72、45 亿元。如果市场的最大需求量只有 20 万吨,那么我们最大收益策略应该是卖出全部 15 万吨第 2 种月饼、以及 5 万吨第 3 种月饼,获得 72 + 45/2 = 94.5(亿元)。
输入格式:
每个输入包含一个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N 表示月饼的种类数、以及不超过 500(以万吨为单位)的正整数 D 表示市场最大需求量。随后一行给出 N 个正数表示每种月饼的库存量(以万吨为单位);最后一行给出 N 个正数表示每种月饼的总售价(以亿元为单位)。数字间以空格分隔。
输出格式:
对每组测试用例,在一行中输出最大收益,以亿元为单位并精确到小数点后 2 位。
输入样例:
3 20
18 15 10
75 72 45
输出样例:
94.50
代码:
一些感慨: 看到题目直接归结为了最值问题,其实不必想得那么麻烦,按照均价降序排列,再计算收益即可
#include <iostream>
#include <algorithm>
#include <iomanip>
using namespace std;
struct Commodity {
float store;
float sale;
float avg;
};
bool cmp(Commodity a1, Commodity a2) {
return a1.avg > a2.avg;
}
int main() {
int kind, need;
Commodity cmd[1000] = { 0 };
float earn = 0;
cin >> kind >> need;
for (int i = 0; i < kind; i++) {
cin >> cmd[i].store;
}
for (int i = 0; i < kind; i++) {
cin >> cmd[i].sale;
cmd[i].avg = cmd[i].sale / cmd[i].store;
}
sort(cmd, cmd + kind, cmp);
for (int i = 0; i < kind && need>0; i++) {
if (cmd[i].store <= need) {
earn += cmd[i].sale;
need -= cmd[i].store;
}
else {
earn += need * cmd[i].avg;
need = 0;
}
}
printf("%.2f", earn);
return 0;
}
1021 个位数统计
给定一个 k 位整数 N,请编写程序统计每种不同的个位数字出现的次数。例如:给定 N=100311,则有 2 个 0,3 个 1,和 1 个 3。
输入格式:
每个输入包含 1 个测试用例,即一个不超过 1000 位的正整数 N。
输出格式:
对 N 中每一种不同的个位数字,以 D:M 的格式在一行中输出该位数字 D 及其在 N 中出现的次数 M。要求按 D 的升序输出。
输入样例:
100311
输出样例:
0:2
1:3
3:1
代码:
积累点: 使用长度为10的int型数组统计各数字出现的个数最方便
#include <iostream>
using namespace std;
int main() {
char num[1001] = {};
int k = 0;
while (cin >> num[k]) {
k++;
}
int count[10] = { 0 };
for (int i = 0; i < 10; i++) {
for (int j = 0; j < k; j++) {
if (num[j] - '0' == i)
count[i]++;
}
}
for (int i = 0; i < 10; i++) {
if (count[i] != 0)
cout << i << ":" << count[i] << endl;
}
return 0;
}
1022 D进制的A+B
输入两个非负 10 进制整数 A 和 B (≤2^30−1),输出 A+B 的 D (1<D≤10)进制数。
输入格式:
输入在一行中依次给出 3 个整数 A、B 和 D。
输出格式:
输出 A+B 的 D 进制数。
输入样例:
123 456 8
输出样例:
1103
代码:
#include <iostream>
using namespace std;
int main() {
int A, B, D;
cin >> A >> B >> D;
int num = A + B, i = 0;
int n[10000] = { 0 };
while (num != 0) {
n[i] = num % D;
num /= D;
i++;
}
if (A + B != 0)
for (int j = i - 1; j >= 0; j--)
cout << n[j];
else
cout << 0;
return 0;
}
1023 组个最小数
给定数字 0-9 各若干个。你可以以任意顺序排列这些数字,但必须全部使用。目标是使得最后得到的数尽可能小(注意 0 不能做首位)。例如:给定两个 0,两个 1,三个 5,一个 8,我们得到的最小的数就是 10015558。
现给定数字,请编写程序输出能够组成的最小的数。
输入格式:
输入在一行中给出 10 个非负整数,顺序表示我们拥有数字 0、数字 1、……数字 9 的个数。整数间用一个空格分隔。10 个数字的总个数不超过 50,且至少拥有 1 个非 0 的数字。
输出格式:
在一行中输出能够组成的最小的数。
输入样例:
2 2 0 0 0 3 0 0 1 0
输出样例:
10015558
代码:
#include <iostream>
using namespace std;
int main() {
int num[10] = { 0 };
bool flag = false;
int nc = 0;
for (int i = 0; i < 10; i++) {
cin >> num[i];
if (i != 0 && num[i] != 0 && flag == false) {
flag = true;
num[i]--;
nc = i;
}
}
cout << nc;
for (int i = 0; i < 10; i++) {
for (int j = 0; j < num[i]; j++) {
cout << i;
}
}
return 0;
}
1024 科学计数法
科学计数法是科学家用来表示很大或很小的数字的一种方便的方法,其满足正则表达式 [+-][1-9].[0-9]+E[+-][0-9]+,即数字的整数部分只有 1 位,小数部分至少有 1 位,该数字及其指数部分的正负号即使对正数也必定明确给出。
现以科学计数法的格式给出实数 A,请编写程序按普通数字表示法输出 A,并保证所有有效位都被保留。
输入格式:
每个输入包含 1 个测试用例,即一个以科学计数法表示的实数 A。该数字的存储长度不超过 9999 字节,且其指数的绝对值不超过 9999。
输出格式:
对每个测试用例,在一行中按普通数字表示法输出 A,并保证所有有效位都被保留,包括末尾的 0。
输入样例 1:
+1.23400E-03
输出样例 1:
0.00123400
输入样例 2:
-1.2E+10
输出样例 2:
-12000000000
代码:
- 最后一个测试点未能通过
#include <iostream>
#include <iomanip>
#include <math.h>
#include <cstring>
using namespace std;
int main() {
char input[9999] = {};
cin >> input;
int idx = 1, dot = 0;
int num = 0;
char pn1 = input[0];
while (input[idx] != 'E') {
if (input[idx] == '.') {
dot = idx;
idx++;
}
else {
num = num * 10 + (input[idx] - '0');
idx++;
}
}
int idx_E = idx;
int len = idx - 2;
int pn2;
if (input[idx + 1] == '+')
pn2 = 1;
else
pn2 = -1;
int zero = 0;
idx += 2;
while (true) {
if (input[idx] != '\0') {
zero = zero * 10 + (input[idx] - '0');
idx++;
}
else
break;
}
if (pn1 == '-')
cout << pn1;
int move = -1 * pn2 * zero + (idx_E - dot - 1); //取往左挪为正
if (move < 0) {
cout << num;
for (int i = 0; i < -move; i++) {
cout << 0;
}
}
else if (move >= 0) {
if (move - len > 0) {
cout << "0.";
for (int i = 0; i < move - len; i++) {
cout << 0;
}
cout << num;
}
else if (move - len == 0) {
cout << 0;
char output[9999] = {};
for (int i = len - 1; i >= 0; i--) {
output[i] = num % 10 + '0';
num /= 10;
}
for (int i = 0; i < len; i++) {
if (i == len - move) {
cout << ".";
}
cout << output[i];
}
}
else {
char output[9999] = {};
for (int i = len - 1; i >= 0; i--) {
output[i] = num % 10 + '0';
num /= 10;
}
if (zero != 0) {
for (int i = 0; i < len; i++) {
if (i == len - move) {
cout << ".";
}
cout << output[i];
}
}
else {
for (int i = 0; i < len; i++) {
if (i == 1) {
cout << ".";
}
cout << output[i];
}
}
}
}
return 0;
}
以下是2025年5月14日开始的刷题记录,愿保研顺利:
🧠 刷题时哈希表设计 4 大核心原则
| 目标 | 哈希表设计 |
|---|---|
| 快速查某个数是否出现过 | unordered_set<int> s; 用 s.count(x) 判断是否存在 |
| 快速找值对应的下标 | unordered_map<int, int> num_to_index; |
| 计数 / 统计频次 | unordered_map<int, int> counter; |
| 根据一个值找另一个值 | unordered_map<key_type, value_type> map; 如 字符 → 出现位置 |
📚 通用模板题型与哈希表设计
① Two Sum 类题(找满足关系的两个数)
题型:
给你一个数组和一个目标值,找两个数使得它们的和为目标值,返回下标。
哈希表设计:
unordered_map<int, int> num_to_index; // 数 → 下标
模板逻辑:
for (int i = 0; i < nums.size(); ++i) {
int complement = target - nums[i];
if (num_to_index.count(complement)) {
return {num_to_index[complement], i};
}
num_to_index[nums[i]] = i;
}
② 数字频率统计(如多数元素)
题型:
找出现次数超过 n/2 的数
哈希表设计:
unordered_map<int, int> freq; // 数 → 次数
模板逻辑:
for (int num : nums) {
freq[num]++;
if (freq[num] > nums.size() / 2)
return num;
}
③ 字符串/数组中是否存在重复元素
题型:
给一个数组,问是否存在重复元素。
哈希表设计:
unordered_set<int> seen; // 只关心是否存在
模板逻辑:
for (int num : nums) {
if (seen.count(num)) return true;
seen.insert(num);
}
return false;
④ 子数组和为 k 的个数
题型:
求多少个连续子数组和为 k
哈希表设计:
unordered_map<int, int> prefix_sum_count;
模板逻辑:
int sum = 0, count = 0;
prefix_sum_count[0] = 1;
for (int num : nums) {
sum += num;
if (prefix_sum_count.count(sum - k))
count += prefix_sum_count[sum - k];
prefix_sum_count[sum]++;
}
return count;
🔧 小技巧
| 技巧 | 说明 |
|---|---|
count(x) | 判断某个 key 是否存在 |
find(x) + ->second | 找到并获取对应的 value |
map[key]++ | 统计次数 |
set.insert(x) | 插入值 |
map[key] = value | 映射关系建立 |
✅ 一句话记住哈希表:
用哈希表的核心动机:换掉“循环查找” → 一步查到,时间降为 O(1)。